计算机网络(2)——网络编程BIO、NIO
本来在学习nginx,想写一些nginx的blog,但是在看一写blog的时候,看到了io多路复用,epoll等概念,确认过眼神,是没学过的概念,于是由转而看起了网络编程多线程相关的一些知识,也是学到了很多新的知识。
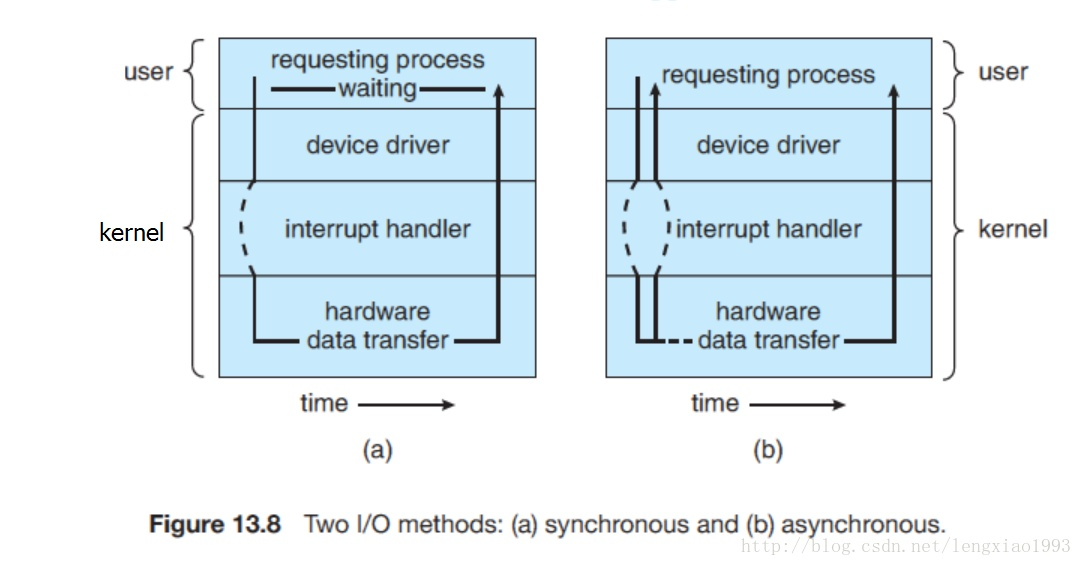
一. 同步、异步、阻塞、非阻塞 同步、异步是两种通信机制,同步是指在调用函数的时候,必须要有返回结果才能够继续往下执行;异步则是指,调用在发出的时候,调用者不会立刻得到结果,而是在调用发出之后,被调用者通过状态、通知来通知调用者,或者通过回调函数处理这个调用。
而阻塞和非阻塞是种状态,它们关注的是程序在等待结果时的状态,阻塞是指程序在调用结果返回直线,当前线程会被挂起,只有在得到结果之后才能返回。这种被挂起的状态被称为阻塞。非阻塞是指线程在结果返回之前不会被挂起,该调用会执行其他的事情。
同步IO可以分为阻塞IO和非阻塞IO,我们之后谈论的BIO就是阻塞IO,NIO是非阻塞IO,而aio就是异步io。
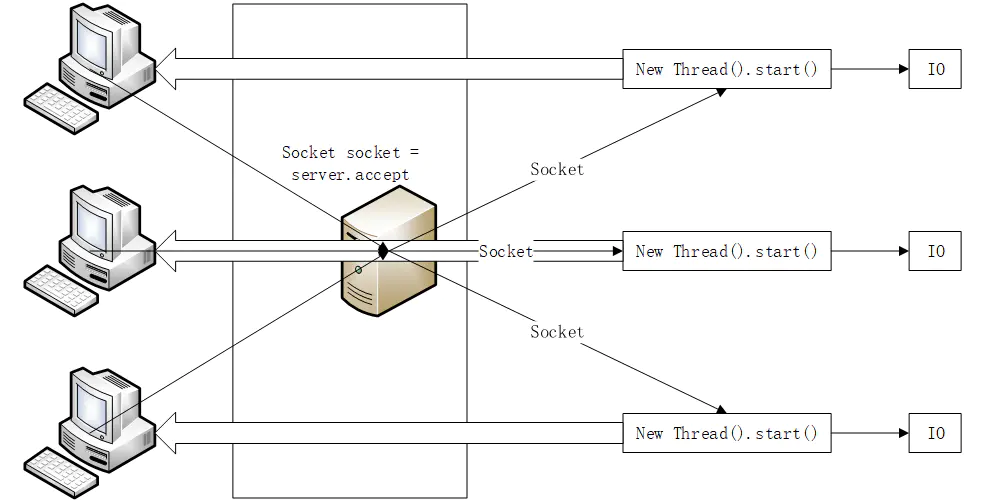
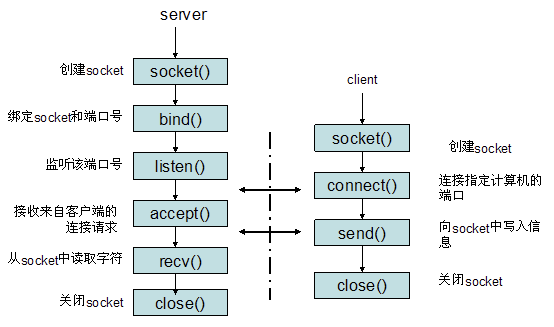
二. BIO模型 BIO又叫做blocking IO,阻塞模型,下面我们来说BIO流程,注意下面所说的都是针对多线程的。
BIOServer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package bio;import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;import java.net.ServerSocket;import java.net.Socket;public class BIOServer private static int PORT = 12345 ; private static ServerSocket server; public static void start () throws IOException start(PORT); } public synchronized static void start (int port) throws IOException if (server != null ) return ; try { server = new ServerSocket(port); System.out.println("服务器已启动, 端口号:" + port); while (true ){ Socket socket = server.accept(); new Thread(new BIOServerHandler(socket)).start(); } }finally { if (server != null ){ System.out.println("服务器关闭" ); server.close(); server = null ; } } } }
BIO服务端交互代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 package bio;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.io.PrintWriter;import java.net.Socket;public class BIOServerHandler implements Runnable private Socket socket; public BIOServerHandler (Socket socket) this .socket = socket; } @Override public void run () BufferedReader in = null ; PrintWriter out = null ; try { in = new BufferedReader(new InputStreamReader(socket.getInputStream())); out = new PrintWriter(socket.getOutputStream(), true ); String expression; String result; while (true ){ if ((expression = in.readLine()) == null ) break ; System.out.println("服务器收到消息:" + expression); try { result = "to do!" ; }catch (Exception e){ result = "计算错误" + e.getMessage(); } out.println(result); } }catch (Exception e){ e.printStackTrace(); }finally { if (in != null ){ try { in.close(); }catch (IOException e){ e.printStackTrace(); } } if (out != null ){ out.close(); out = null ; } if (socket!= null ){ try { socket.close(); }catch (IOException e){ e.printStackTrace(); } socket = null ; } } } }
BIOClient
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 package bio;import javax.print.DocFlavor;import java.io.*;import java.net.Socket;public class BIOClient private static int PORT = 12345 ; private static String IP = "localhost" ; public static void send (String expression) send(PORT, expression); } public static void send (int port, String expression) System.out.println("发送消息为:" + expression); Socket socket = null ; BufferedReader in = null ; PrintWriter out = null ; try { socket = new Socket(IP, PORT); in = new BufferedReader(new InputStreamReader(socket.getInputStream())); out = new PrintWriter(socket.getOutputStream(),true ); out.println(expression); System.out.println("结果为:" + in.readLine()); }catch (Exception e){ e.printStackTrace(); }finally { if (in != null ){ try { in.close(); } catch (IOException e) { e.printStackTrace(); } in = null ; } if (out != null ){ out.close(); out = null ; } if (socket != null ){ try { socket.close(); } catch (IOException e) { e.printStackTrace(); } socket = null ; } } } }
测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package bio;import java.io.IOException;import java.net.ServerSocket;import java.util.Random;public class Test public static void main (String[] args) throws InterruptedException new Thread(new Runnable() { @Override public void run () try { BIOServer.start(); } catch (IOException e) { e.printStackTrace(); } } }).start(); Thread.sleep(100 ); char operators[] = {'+' ,'-' ,'*' ,'/' }; Random random = new Random(System.currentTimeMillis()); new Thread(new Runnable() { @Override public void run () while (true ){ String expression = random.nextInt(10 )+"" +operators[random.nextInt(4 )]+(random.nextInt(10 )+1 ); BIOClient.send(expression); try { Thread.currentThread().sleep(random.nextInt(1000 )); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); } }
BIO的只适用与小并发量且是一问一答的程序,因为每有一个客户端连接进来,服务端就会创建一个新的线程用于对接,线程也会占用内存资源,并且创建线程需要进行系统调用,当线程数量快速膨胀后,cpu需要不断切换线程,这样上下文切换将会占用cpu大量的时间。最重要的缺点是accept是阻塞的,这是无法解决根本问题的,而NIO作为非阻塞模型,就可以很好解决这个问题。
三. NIO模型 Nio官方叫法new io,我们习惯称之为no-block io应为非阻塞是nio的最大的特点。对于NIO,如果TCP RecvBUffer有数据,就把数据从网卡读到内存,并且返回给用户;反之则返回0,永远不会阻塞。在NIO中用户最关心的是,“我可以读了”。本质上来说,NIO模型中,socket主要的读写、注册、接收函数,在等待就绪阶段是非堵塞的,真正的IO操作是同步阻塞的。
NIO最重要的三个基本概念是channel、buffer、selector。
1.channel channel 我们通过翻译可以看出,它是一个通道,可以与硬件如网卡、硬盘进行连接,当通道被被打开时,我们可以向通道中读写数据。和流的概念类似但是通道是双向的,而流只具有单向性,并且通道可以支持多线程的读写,比较重要的的一些通道如FileChannel、ServerSocketChannel、SocketChannel都是现在比较常用的类,再多线程中发挥着重要作用,由于我们这只将网络编程,所以我下面重点介绍ServerSocketChannel、SocketChannel。
ServerSocketChannel
ServerSocketChannel 是用于TCP服务端的通道,他的作用和标准IO中的ServerSocket类似,可以绑定端口进行监听。和ServerSocket相比,ServerSocketChannel最大的优势是可以设置为非阻塞的状态,当没有客户端连接进来时,ServerSocketChannel可以立刻返回null,如果有客户端连接时,就会和ServerSocket一样返回一个Socket,除此之外ServerSocketChannel是多线程安全的,支持多线程并发。
SocketChannel
SocketChannel 是用于TCP客户端的通道,它同样可以设置非阻塞模式对服务端进行连接,以及对通道内的数据进行读写。SocketChannel还有一个特点就是支持异步关闭,如果SocketChannel在一个线程上read阻塞,另一个线程对该SocketChannel调用shutdownInput,则读阻塞的线程将返回-1表示没有读取任何数据;如果SocketChannel在一个线程上write阻塞,另一个线程对该SocketChannel调用shutdownOutput,则写阻塞的线程将抛出AsynchronousCloseException。
2.buffer Buffer通常与Channel进行交互,数据从通道读入缓冲区,或者从缓冲区写入通道中,缓冲区本质上是一个可以写入数据的数组,之后可以读取数据,Buffer对象包装了此内存块,可以更轻松的使用内存块。
使用buffer时通常遵循以下几个步骤:
将数据写入缓冲区
调用buffer.flip()反转读写模式
从缓冲区读取数据
调用buffer.clear()或者buffer.compact()清除缓冲区的内容。
将数据写入Buffer 时,Buffer 会跟踪写入的数据量。 当需要读取数据时,就使用 flip() 方法将缓冲区从写入模式切换到读取模式。 在读取模式下,缓冲区允许读取写入缓冲区的所有数据。
读完所有数据之后,就需要清除缓冲区,以便再次写入。 可以通过两种方式执行此操作:通过调用 clear() 或调用 compact() 。区别在于 clear() 是方法清除整个缓冲区,而 compact() 方法仅清除已读取的数据,未读数据都会移动到缓冲区的开头,新数据将在未读数据之后写入缓冲区。
buffer有一些基本概念:
capacity:指的时缓冲区的容量,是他所包含的元素的数量,不能为负并且不能够更改。
position:缓冲去的位置, 是下一个要读取或者要写入的元素的索引。不能为负,并且不能够大于limit
limit:缓冲区的限制,缓冲区的限制不能为负,并且不能够大于capacity
另外还有标记 mark ,
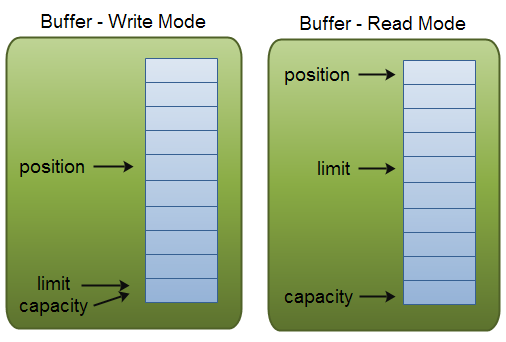
position和limit的含义取决于Buffer是处于读取还是写入模式。无论缓冲模式如何,capacity总是一样表示容量。
以下是写入和读取模式下的容量,位置和限制的说明:
capacity
作为存储器块,缓冲区具有一定的固定大小,也称为“容量”。 只能将 capacity 多的 byte,long,char 等写入缓冲区。 缓冲区已满后,需要清空它(读取数据或清除它),然后才能将更多数据写入。
position
将数据写入缓冲区时,可以在某个位置执行操作。 position 初始值为 0 ,当一个 byte,long,char 等已写入缓冲区时,position 被移动,指向缓冲区中的下一个单元以插入数据。 position 最大值为 capacity -1
从缓冲区读取数据时,也可以从给定位置开始读取数据。 当缓冲区从写入模式切换到读取模式时,position 将重置为 0 。当从缓冲区读取数据时,将从 position 位置开始读取数据,读取后会将 position 移动到下一个要读取的位置。
limit
在写入模式下,Buffer 的 limit 是可以写入缓冲区的数据量的限制,此时 limit=capacity。
将缓冲区切换为读取模式时,limit 表示最多能读到多少数据。 因此,当将 Buffer 切换到读取模式时,limit被设置为之前写入模式的写入位置(position ),换句话说,你能读到之前写入的所有数据(例如之前写写入了 6 个字节,此时 position=6 ,然后切换到读取模式,limit 代表最多能读取的字节数,因此 limit 也等于 6)。
分配缓冲区
1 ByteBuffer buffer = ByteBuffer.allocate(48 );
将数据写入缓冲区
将数据从通道写入缓冲区
通过缓冲区的 put() 方法,自己将数据写入缓冲区。
1 2 int data = fileChannel.read(buffer); buffer.put(127 );
flip() 切换缓冲区的读写模式
从缓冲区读取数据
将数据从缓冲区读入通道。
使用 get() 方法之一,自己从缓冲区读取数据。
1 2 int bytesWritten = fileChannel.write(buffer);byte aByte = buffer.get();
和 put() 方法一样,get() 方法也有许多其他版本,允许以多种不同方式从 Buffer 中读取数据。有关更多详细信息,请参阅JavaDoc以获取具体的缓冲区实现。
rewind() 倒带
clear() 和 compact()
如果在调用 clear() 时缓冲区中有任何未读数据,数据将被“遗忘”,这意味着不再有任何标记告诉读取了哪些数据,还没有读取哪些数据。
如果缓冲区中仍有未读数据,并且想稍后读取它,但需要先写入一些数据,这时候应该调用 compact() ,它会将所有未读数据复制到 Buffer 的开头,然后它将 position 设置在最后一个未读元素之后。 limit 属性仍设置为 capacity ,就像 clear() 一样。 现在缓冲区已准备好写入,并且不会覆盖未读数据。
mark() 和 reset()
1 2 3 4 buffer.mark(); buffer.reset();
使用buffer的一些好处
当我们使用buffer和channel共同进行数据传输的时候,channel解决了阻塞的问题,那么buffer解决了什么问题?下面我们看一下buffer和channel的流程图
4 个byte需要读取,若我们使用字节流读取的话就需要进行1024 4/32次IO操作,若我们提前讲数据放入buffer,我们就只需要一次IO操作,其他的操作都是在内存中进行,效率就会高很多。
3.selector Selector是NIO中的一个组件,它负责监控和管理多个Channel从而管理多个网络连接。并可以使用轮询的方式确定那些通道可以读写。通道必须处于非阻塞的模式才能够和选择器一起使用,这意味着无法将FileChannel与Selector一起使用,因为FileChannel无法切换到非阻塞模式。套接字通道则支持。
通常selector通过register()的方法来管理通道,他可以监听四种不同的事件,
Connect 连接
Accept 接收
Read 读
Write 写
一个“发起事件”的通道也被称为“已就绪”事件。 因此,已成功连接到另一台服务器的通道是“连接就绪”。 接受传入连接的服务器套接字通道是“接收就绪”。 准备好要读取的数据的通道“读就绪”。 准备好写入数据的通道称为“写就绪”。
下面结合一个具体的例子我们来操作NIONIOServer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package nio;public class NioServer private static int PORT = 12345 ; private static NIOServerHandle serverhandle; public static void start () start(PORT); } public static synchronized void start (int port) if (serverhandle!=null ) serverhandle.stop(); serverhandle = new NIOServerHandle(port); new Thread(serverhandle,"Server" ).start(); } public static void main (String[] args) start(); } }
NIOServerHandler
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 package nio;import java.io.IOException;import java.net.InetSocketAddress;import java.nio.ByteBuffer;import java.nio.channels.SelectionKey;import java.nio.channels.Selector;import java.nio.channels.ServerSocketChannel;import java.nio.channels.SocketChannel;import java.util.Iterator;import java.util.Set;public class NIOServerHandle implements Runnable private Selector selector; private ServerSocketChannel serverSocketChannel; private volatile boolean started; public NIOServerHandle (int port) try { selector = Selector.open(); serverSocketChannel = ServerSocketChannel.open(); serverSocketChannel.configureBlocking(false ); serverSocketChannel.socket().bind(new InetSocketAddress(port),1024 ); serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT); started = true ; System.out.println("服务器已启动, 端口号" + port); } catch (IOException e) { e.printStackTrace(); System.exit(1 ); } } public void stop () false ;} @Override public void run () while (started){ try { selector.select(1000 ); Set<SelectionKey> keys = selector.selectedKeys(); Iterator<SelectionKey> it = keys.iterator(); SelectionKey key = null ; while (it.hasNext()){ key = it.next(); it.remove(); try { hanleInput(key); }catch (Exception e){ if (key != null ){ key.cancel(); if (key.channel() != null ){ key.channel().close(); } } } } } catch (IOException e) { e.printStackTrace(); } } if (selector != null ){ try { selector.close(); }catch (Exception e){ e.printStackTrace(); } } } public void hanleInput (SelectionKey key) throws IOException if (key.isValid()){ if (key.isAcceptable()){ ServerSocketChannel ssc = (ServerSocketChannel)key.channel(); SocketChannel sc = ssc.accept(); sc.configureBlocking(false ); sc.register(selector,SelectionKey.OP_READ); } if (key.isReadable()){ SocketChannel sc = (SocketChannel)key.channel(); ByteBuffer buffer = ByteBuffer.allocate(1024 ); int readBytes = sc.read(buffer); if (readBytes >0 ){ buffer.flip(); byte [] bytes = new byte [buffer.remaining()]; buffer.get(bytes); String expression = new String(bytes,"UTF-8" ); System.out.println("服务器收到消息:" + expression); String result = "to do" ; doWrite(sc, result); } else if (readBytes<0 ){ key.cancel(); sc.close(); } } } } private void doWrite (SocketChannel channel, String response) throws IOException byte [] bytes = response.getBytes(); ByteBuffer writeBuffer = ByteBuffer.allocate(bytes.length); writeBuffer.put(bytes); writeBuffer.flip(); channel.write(writeBuffer); } }
NIOClient
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package nio;public class NIOClient private static String HOST = "localhost" ; private static int PORT = 12345 ; private static NIOClientHandle clientHandle; public static void start () start(HOST,PORT); } private static synchronized void start (String host, int port) if (clientHandle != null ) clientHandle.stop(); clientHandle = new NIOClientHandle(host,port); new Thread(clientHandle,"Server" ).start(); } public static boolean sendMsg (String msg) throws Exception if (msg.equals("q" )) return false ; clientHandle.sendMsg(msg); return true ; } public static void main (String[] args) start(); } }
NIOClientHandle
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 package nio;import java.io.IOException;import java.net.InetSocketAddress;import java.nio.ByteBuffer;import java.nio.channels.ClosedChannelException;import java.nio.channels.SelectionKey;import java.nio.channels.Selector;import java.nio.channels.SocketChannel;import java.util.Iterator;import java.util.Set;public class NIOClientHandle implements Runnable private String host; private int port; private Selector selector; private SocketChannel socketChannel; private volatile boolean started; public NIOClientHandle (String host, int port) this .host = host; this .port = port; try { selector = Selector.open(); socketChannel = SocketChannel.open(); socketChannel.configureBlocking(false ); started = true ; }catch (IOException e){ e.printStackTrace(); System.exit(1 ); } } public void stop () started = false ; } @Override public void run () try { doConnect(); }catch (IOException e){ e.printStackTrace(); System.exit(1 ); } while (started){ try { selector.select(1000 ); Set<SelectionKey> keys = selector.selectedKeys(); Iterator<SelectionKey> it = keys.iterator(); SelectionKey key = null ; while (it.hasNext()){ key = it.next(); it.remove(); try { handleInput(key); }catch (Exception e){ if (key != null ){ key.cancel(); if (key.channel() != null ){ key.channel().close(); } } } } } catch (IOException e) { e.printStackTrace(); System.exit(1 ); } } if (selector != null ) try { selector.close(); }catch (Exception e) { e.printStackTrace(); } } private void doConnect () throws IOException if (socketChannel.connect(new InetSocketAddress(host,port))); else socketChannel.register(selector, SelectionKey.OP_CONNECT); } public void sendMsg (String msg) throws IOException socketChannel.register(selector, SelectionKey.OP_READ); doWrite(socketChannel, msg); } private void doWrite (SocketChannel channel,String request) throws IOException byte [] bytes = request.getBytes(); ByteBuffer writeBuffer = ByteBuffer.allocate(bytes.length); writeBuffer.put(bytes); writeBuffer.flip(); channel.write(writeBuffer); } private void handleInput (SelectionKey key) throws IOException if (key.isValid()){ SocketChannel sc = (SocketChannel) key.channel(); if (key.isConnectable()){ if (sc.finishConnect()); else System.exit(1 ); } if (key.isReadable()){ ByteBuffer buffer = ByteBuffer.allocate(1024 ); int readBytes = sc.read(buffer); if (readBytes>0 ){ buffer.flip(); byte [] bytes = new byte [buffer.remaining()]; buffer.get(bytes); String result = new String(bytes,"UTF-8" ); System.out.println("客户端收到消息:" + result); } else if (readBytes<0 ){ key.cancel(); sc.close(); } } } } }
Test
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package nio;import java.util.Scanner;public class Test public static void main (String[] args) throws Exception NioServer.start(); Thread.sleep(100 ); NIOClient.start(); while (NIOClient.sendMsg(new Scanner(System.in).nextLine())); } }
参考文献 怎样理解阻塞非阻塞与同步异步的区别? Java 网络IO编程总结(BIO、NIO、AIO均含完整实例代码) BIO/NIO底层原理分析 清华大牛权威讲解nio,epoll,多路复用,更好的理解redis-netty-Kafka等热门技术 Java NIO浅析 SocketChannel简述 Java NIO 学习笔记(一)—-概述,Channel/Buffer