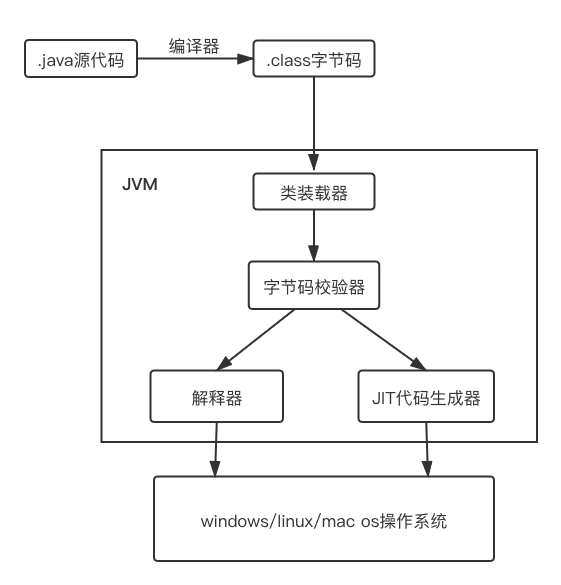
一. 类加载机制概念 我们前面讲到了JVM的工作原理说到,对JAVA源代码编译出来的.class字节码文件,需要通过JVM将字节码转化为底层可识别的机器码,而第一步就是将class文件中的类描述数据加载到虚拟机中。并对数据进行校验、转换解析、初始化,使这些数据最终成为可以被JVM直接使用的Java类型,我们称这样的步骤叫做JVM的类加载机制。
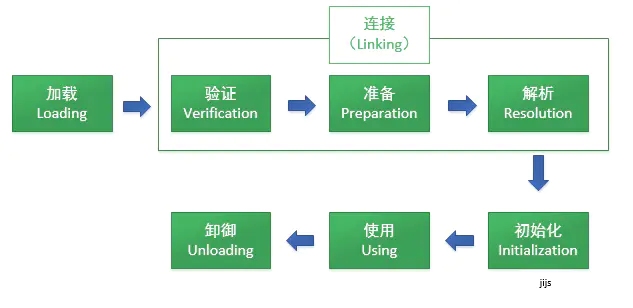
二. 类加载过程 类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载、验证、准备、解析、初始化、使用和卸载七个阶段。其中验证、准备、解析3个阶段统称为连接,它们开始的顺序如下图所示:
这里加载、连接、初始化是在JVM装载器中进行的。在这五个阶段中,加载、验证、准备和初始化这四个阶段发生的顺序是确定的,而解析阶段则不一定,它在某些情况下可以在初始化阶段之后开始,这是为了支持Java语言的运行时绑定(也成为动态绑定或晚期绑定)。另外注意这里的几个阶段是按顺序开始,而不是按顺序进行或完成,因为这些阶段通常都是互相交叉地混合进行的,通常在一个阶段执行的过程中调用或激活另一个阶段。
这里简要说明下Java中的绑定:绑定指的是把一个方法的调用与方法所在的类(方法主体)关联起来,对java来说,绑定分为静态绑定和动态绑定:
静态绑定:即前期绑定。在程序执行前方法已经被绑定,此时由编译器或其它连接程序实现。针对java,简单的可以理解为程序编译期的绑定。java当中的方法只有final,static,private和构造方法是前期绑定的。
动态绑定:即晚期绑定,也叫运行时绑定。在运行时根据具体对象的类型进行绑定。在java中,几乎所有的方法都是后期绑定的。
下面我们具体介绍加载、连接、初始化这三个过程。
1. 加载 加载时类加载过程的第一个阶段,在加载阶段,虚拟机需要完成以下三件事情:
通过一个类的全限定名来获取其定义的二进制字节流。
将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
这样说起来有些难以理解,我们可以举一个简单的例子,
1 2 3 4 5 6 7 8 9 package ClassLoaderTest;public class Example1 static int a = 1 ; public static void main (String[] args) System.out.println(Example1.a); } }
我们在类中初始化了一个static int类型的元素a,在加载这个类时,JVM首先会从classpath路径下找到一个叫Example1.class的字节流文件,然后将此字节流文件中的静态数据和静态代码块(这里指的就是我们的static int a)放入到方法区内,并在内存中生成一个Example1对象,这个对象是java.lang.Class类型的(由加载器提取并放入堆中) ,可以用来访问方法区内属于这个类的各种数据。这里我们Example1.a就是访问可存在方法区中的static int类型元素。
值得注意的是class对象也是存放在堆中,方法区中存放的只是类型数据
类的加载方式有很多种,可以从JAR包中、网络获取、JSP文件生成Class文件、从数据库中获取等。
相对于类加载的其他阶段而言,加载阶段(准确地说,是加载阶段获取类的二进制字节流的动作)是可控性最强的阶段,因为开发人员既可以使用系统提供的类加载器来完成加载,也可以自定义自己的类加载器来完成加载。这里就需要对类加载器有充分的了解,我会在后续详细介绍不同的类加载器。
我们需要注意数组类和非数组类的加载是有一定区别的。 数组本身不是通过类加载器创建的,它是通过JAVA虚拟机直接创建的,但是数组中的元素类型最终是靠类加载器创建,一个类加载器遵循一下规则:
如果数组的组件类型(指的是数组去掉一个维度的类型)是引用类型,那就递归采用本节中定义的加载过程去加载这个组件类型,数组C将在加载该组件类型的类加载器的类名称空间被标识
如果数组的组件类型不是引用类型(例如int[]数组),java虚拟机将会吧数组C标记为于引导类加载器相关联
数组类的可见性与他的组件类型相一致,如果组件不是引用类型,那数组类型的可见性默认为public
我们看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 package ClassLoaderTest;public class Example2 static int a =1 ; public static void main (String[] args) Example2 [] a = new Example2[5 ]; Example2 b = new Example2(); System.out.println(a.getClass()); System.out.println(b.getClass()); } }
getClass()表示的是获取实例的类型类,也就是我们在内存空间生成的java.lang.Class类型结果,结果显示为
1 2 class [LClassLoaderTest.Example2; class ClassLoaderTest.Example2
这里可以看到数组也是一个类,但是数组类型和他的组件类型是不一样的,会有[L来标识数组类型。具体内容可以参考一下这篇内容:如何理解数组在Java中作为一个类?
2. 验证 验证的目的是为了确保Class文件中的字节流包含的信息符合当前虚拟机的要求,而且不会危害虚拟机自身的安全。不同的虚拟机对类验证的实现可能会有所不同,但大致都会完成以下四个阶段的验证:文件格式的验证、元数据的验证、字节码验证和符号引用验证。主要有以下几种验证。
文件格式验证:
元数据验证:
字节码验证:
符号引用验证:
3. 准备 准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中进行分。这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在Java堆中。这里所设置的初始值通常情况下是数据类型默认的零值(如0、0L、null、false等),而不是被在Java代码中被显式地赋予的值。
4. 解析 解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。
符号引用(Symbolic Reference):符号引用以一组符号来描述所引用的目标,符号引用可以是任何形式的字面量,符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经在内存中。
直接引用(Direct Reference):直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是与虚拟机实现的内存布局相关的,同一个符号引用在不同的虚拟机实例上翻译出来的直接引用一般都不相同,如果有了直接引用,那引用的目标必定已经在内存中存在。
类或方法解析: 判断所要转化成的直接引用是对数组类型,还是普通的对象类型的引用,从而进行不同的解析。
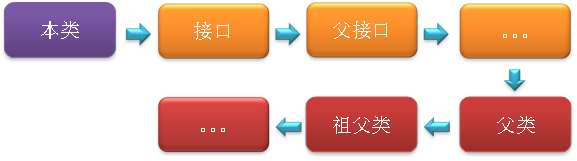
字段解析:对字段进行解析时,会先在本类中查找是否包含有简单名称和字段描述符都与目标相匹配的字段,如果有,则查找结束;如果没有,则会按照继承关系从上下往上递归搜索该类所实现的各个接口和它们的父接口,还没有,则按照继承关系从下往上递归搜索其父类,直至查找结束,查找流程如下图所示:
最后需要注意:理论上是按照上述顺序进行搜索解析,但在实际应用中,虚拟机的编译器实现可能要比上述规范要求的更严格一些。如果有一个同名字段同时出现在该类的接口和父类中,或同时在自己或父类的接口中出现,编译器可能会拒绝编译。
4. 初始化 初始化是类加载过程的最后一步,到了此阶段,才真正开始执行类中定义的Java程序代码。在准备阶段,类变量已经被赋过一次系统要求的初始值,而在初始化阶段,则是根据程序员通过程序指定的主观计划去初始化类变量和其他资源,或者可以从另一个角度来表达:初始化阶段是执行类构造器 <clinit>()方法的过程。
1、<clinit>()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句中可以赋值,但是不能访问。
2、<clinit>()方法与实例构造器<init>()方法(类的构造函数)不同,它不需要显式地调用父类构造器,虚拟机会保证在子类的<clinit>()方法执行之前,父类的<clinit>()方法已经执行完毕。因此,在虚拟机中第一个被执行的<clinit>()方法的类肯定是java.lang.Object。
3、<clinit>()方法对于类或接口来说并不是必须的,如果一个类中没有静态语句块,也没有对类变量的赋值操作,那么编译器可以不为这个类生成<clinit>()方法。
4、接口中不能使用静态语句块,但仍然有类变量(final static)初始化的赋值操作,因此接口与类一样会生成<clinit>()方法。但是接口鱼类不同的是:执行接口的<clinit>()方法不需要先执行父接口的<clinit>()方法,只有当父接口中定义的变量被使用时,父接口才会被初始化。另外,接口的实现类在初始化时也一样不会执行接口的<clinit>()方法。
5、虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确地加锁和同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的<clinit>()方法,其他线程都需要阻塞等待,直到活动线程执行<clinit>()方法完毕。如果在一个类的<clinit>()方法中有耗时很长的操作,那就可能造成多个线程阻塞,在实际应用中这种阻塞往往是很隐蔽的。我们看一段代码来更深入的理解上面的规则:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package ClassLoaderTest;class Father1 public static int a = 1 ; static { a = 2 ; } } class Child1 extends Father1 public static int b = a; } public class ClinitTest public static void main (String[] args) System.out.println(Child1.b); } }
此时的结果是 2
我们来看得到该结果的步骤。首先在准备阶段为类变量分配内存并设置类变量初始值,这样A和B均被赋值为默认值0,而后再在调用()方法时给他们赋予程序中指定的值。当我们调用Child.b时,触发Child的()方法,根据规则2,在此之前,要先执行完其父类Father的()方法,又根据规则1,在执行()方法时,需要按static语句或static变量赋值操作等在代码中出现的顺序来执行相关的static语句,因此当触发执行Father的()方法时,会先将a赋值为1,再执行static语句块中语句,将a赋值为2,而后再执行Child类的()方法,这样便会将b的赋值为2.
如果我们颠倒一下Father类中“public static int a = 1;”语句和“static语句块”的顺序,程序执行后,则会打印出1。很明显是根据规则1,执行Father的()方法时,根据顺序先执行了static语句块中的内容,后执行了“public static int a = 1;”语句。
另外,在颠倒二者的顺序之后,如果在static语句块中对a进行访问(比如将a赋给某个变量),在编译时将会报错,因为根据规则1,它只能对a进行赋值,而不能访问。
Java虚拟机规范中严格规定了有且只有五种情况必须对类进行初始化:
使用new字节码指令创建类的实例,或者使用getstatic、putstatic读取或设置一个静态字段的值(放入常量池中的常量除外),或者调用一个静态方法的时候,对应类必须进行过初始化。
通过java.lang.reflect包的方法对类进行反射调用的时候,如果类没有进行过初始化,则要首先进行初始化。
当初始化一个类的时候,如果发现其父类没有进行过初始化,则首先触发父类初始化。
当虚拟机启动时,用户需要指定一个主类(包含main()方法的类),虚拟机会首先初始化这个类。
使用jdk1.7的动态语言支持时,如果一个java.lang.invoke.MethodHandle实例最后的解析结果REF_getStatic、REF_putStatic、RE_invokeStatic的方法句柄,并且这个方法句柄对应的类没有进行初始化,则需要先触发其初始化。
注意,虚拟机规范使用了“有且只有”这个词描述,这五种情况被称为“主动引用”,除了这五种情况,所有其他的类引用方式都不会触发类初始化,被称为“被动引用”。
被动引用的例子一:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class SuperClass public static int value = 666 ; static { System.out.println("父类初始化!" ); } } public class SubClass extends SuperClass static { System.out.println("子类初始化!" ); } } public class NotInit public static void main (String[] args) System.out.println(SubClass.value); } }
输出结果为:
父类初始化
被动引用的例子二:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class SuperClass public static int value = 666 ; static { System.out.println("父类初始化!" ); } } public class NotInit public static void main (String[] args) SuperClass[] test = new SuperClass[10 ]; } }
结果为空白,这里没有触发类SuperClass的初始化阶段,但是会触发[lSuperClass的类初始化,它是由虚拟机自动生成的,这我们在前面的加载这一阶段中已经提到了。
被动引用例子三:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class ConstClass static { System.out.println("常量类初始化!" ); } public static final String HELLOWORLD = "hello world!" ; } public class NotInit public static void main (String[] args) System.out.println(ConstClass.HELLOWORLD); } }
结果只会输出hell world!不会输出常量类初始化,这是因为final是修饰的HELLOWORLD在编译阶段通过常量传播优化,已经将常量的值”hello world!”存储在NotInit类的敞亮池中,以后NotInit对常量ConstClass.HELLOWORLD的引用实际都会被转化为NotInit类对自身常量池的引用。也就是说NotInit类的Class文件实际上并没有ConstClass类的符号引用入口,这两个类在编译成Class文件之后就没有关系了。
三. 类加载器 JVM设计者把类加载阶段中的“通过’类全名’来获取定义此类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。实现这个动作的代码模块称为“类加载器”。
1.类与类加载器
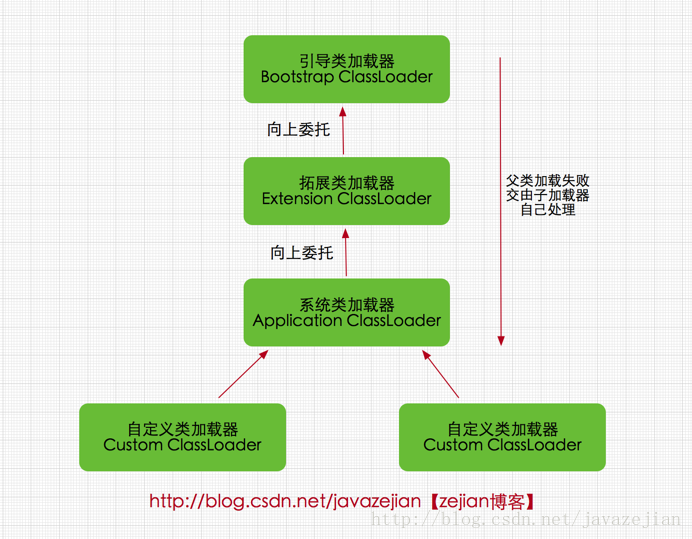
2. 类加载器分类 /lib路径下的核心类库或-Xbootclasspath参数指定的路径下的jar包加载到内存中,在工作中它负责加载扩展类加载器和系统类加载器,并作为这些加载器的父加载器,注意必由于虚拟机是按照文件名识别加载jar包的,如rt.jar,如果文件名不被虚拟机识别,即使把jar包丢到lib目录下也是没有作用的(出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类)。
扩展类加载器:
系统类加载器或称为应用程序类加载器:
在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的,在必要时,我们还可以自定义类加载器,需要注意的是,Java虚拟机对class文件采用的是按需加载的方式,也就是说当需要使用该类时才会将它的class文件加载到内存生成class对象,而且加载某个类的class文件时,Java虚拟机采用的是双亲委派模式即把请求交由父类处理,它一种任务委派模式,下面我们进一步了解它。
双亲委派模型 双亲委派模型原理:
双亲委派模型优势
1 java.lang.SecurityException: Prohibited package name: java.lang
双亲委派破坏
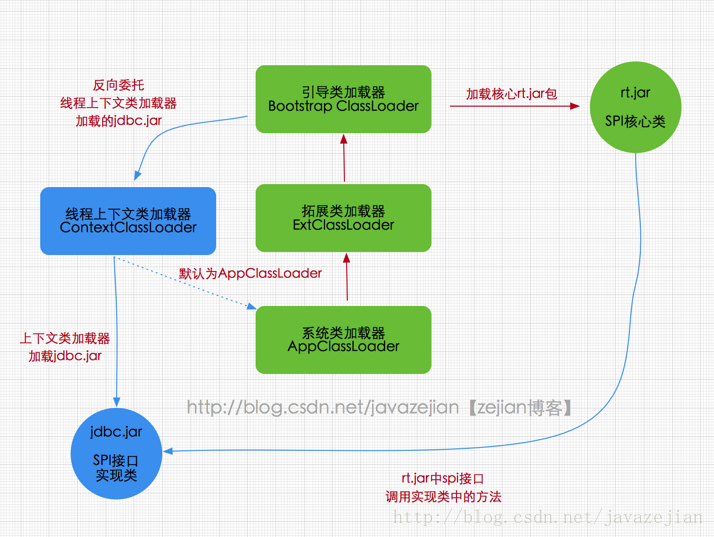
在Java应用中存在着很多服务提供者接口(Service Provider Interface,SPI),这些接口允许第三方为它们提供实现,如常见的 SPI 有 JDBC、JNDI等,这些 SPI 的接口属于 Java 核心库,一般存在rt.jar包中,由Bootstrap类加载器加载,而 SPI 的第三方实现代码则是作为Java应用所依赖的 jar 包被存放在classpath路径下,由于SPI接口中的代码经常需要加载具体的第三方实现类并调用其相关方法,但SPI的核心接口类是由引导类加载器来加载的,而Bootstrap类加载器无法直接加载SPI的实现类,同时由于双亲委派模式的存在,Bootstrap类加载器也无法反向委托AppClassLoader加载器SPI的实现类。在这种情况下,我们就需要一种特殊的类加载器来加载第三方的类库,而线程上下文类加载器就是很好的选择。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class DriverManager static { loadInitialDrivers(); println("JDBC DriverManager initialized" ); } private static void loadInitialDrivers () sun.misc.Providers() AccessController.doPrivileged(new PrivilegedAction<Void>() { public Void run () ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class ) ; } }); }
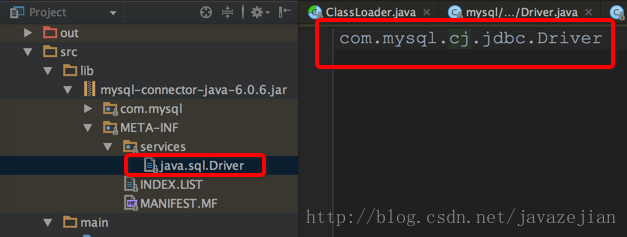
在DriverManager类初始化时执行了loadInitialDrivers()方法,在该方法中通过ServiceLoader.load(Driver.class);去加载外部实现的驱动类,ServiceLoader类会去读取mysql的jdbc.jar下META-INF文件的内容,如下所示
而com.mysql.jdbc.Driver继承类如下:
1 2 3 4 5 6 7 8 9 10 11 public class Driver extends com .mysql .cj .jdbc .Driver public Driver () throws SQLException super (); } static { System.err.println("Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. " + "The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary." ); } }
从注释可以看出平常我们使用com.mysql.jdbc.Driver已被丢弃了,取而代之的是com.mysql.cj.jdbc.Driver,也就是说官方不再建议我们使用如下代码注册mysql驱动
1 2 3 4 5 6 7 Class.forName("com.mysql.jdbc.Driver" ); String url = "jdbc:mysql://localhost:3306/cm-storylocker?characterEncoding=UTF-8" ; Connection conn = java.sql.DriverManager.getConnection(url, "root" , "root@555" );
而是直接去掉注册步骤,如下即可
1 2 3 String url = "jdbc:mysql://localhost:3306/cm-storylocker?characterEncoding=UTF-8" ; Connection conn = java.sql.DriverManager.getConnection(url, "root" , "root@555" );
这样ServiceLoader会帮助我们处理一切,并最终通过load()方法加载,看看load()方法实现
1 2 3 4 5 public static <S> ServiceLoader<S> load (Class<S> service) { ClassLoader cl = Thread.currentThread().getContextClassLoader(); return ServiceLoader.load(service, cl); }
很明显了确实通过线程上下文类加载器加载的,实际上核心包的SPI类对外部实现类的加载都是基于线程上下文类加载器执行的,通过这种方式实现了Java核心代码内部去调用外部实现类。我们知道线程上下文类加载器默认情况下就是AppClassLoader,那为什么不直接通过getSystemClassLoader()获取类加载器来加载classpath路径下的类的呢?其实是可行的,但这种直接使用getSystemClassLoader()方法获取AppClassLoader加载类有一个缺点,那就是代码部署到不同服务时会出现问题,如把代码部署到Java Web应用服务或者EJB之类的服务将会出问题,因为这些服务使用的线程上下文类加载器并非AppClassLoader,而是Java Web应用服自家的类加载器,类加载器不同。,所以我们应用该少用getSystemClassLoader()。总之不同的服务使用的可能默认ClassLoader是不同的,但使用线程上下文类加载器总能获取到与当前程序执行相同的ClassLoader,从而避免不必要的问题。ok~.关于线程上下文类加载器暂且聊到这,前面阐述的DriverManager类,大家可以自行看看源码,相信会有更多的体会,另外关于ServiceLoader本篇并没有过多的阐述,毕竟我们主题是类加载器,但ServiceLoader是个很不错的解耦机制,大家可以自行查阅其相关用法。
面试题、 下面我们看一些面试来回顾一下学习的内容,这也是为以后面试做的一些准备吧。
看你简历写得熟悉JVM,那你说说类的加载过程吧?
我们可以自定义一个String类来使用吗?(判断类的唯一性)
什么是类加载器,类加载器有哪些?
多线程的情况下,类的加载为什么不会出现重复加载的情况?
什么是双亲委派机制?它有啥优势?可以打破这种机制吗?
参考文章 视频:
尚硅谷宋红康JVM教程(java虚拟机详解,jvm从入门到精通)
文章:
Java类加载机制(全套) Java 类加载机制(阿里)-何时初始化类 【深入Java虚拟机】之四:类加载机制 【深入Java虚拟机】之三:类初始化 JVM类加载机制详解(二)类加载器与双亲委派模型 深入理解Java类加载器(ClassLoader)